RAG-检索优化
混合检索
混合检索(Hybrid Search)是一种结合了 稀疏向量(Sparse Vectors) 和 密集向量(Dense Vectors) 优势的先进搜索技术。旨在同时利用稀疏向量的关键词精确匹配能力和密集向量的语义理解能力,以克服单一向量检索的局限性,从而在各种搜索场景下提供更准确、更鲁棒的检索结果。
稀疏向量
稀疏向量,也常被称为“词法向量”,是基于词频统计的传统信息检索方法的数学表示。它通常是一个维度极高(与词汇表大小相当)但绝大多数元素为零的向量。它采用精准的“词袋”匹配模型,将文档视为一堆词的集合,不考虑其顺序和语法,其中向量的每一个维度都直接对应一个具体的词,非零值则代表该词在文档中的重要性(权重)。这类向量的经典权重计算方法是 TF-IDF。在信息检索领域,BM25 则是基于这种稀疏表示的成功且应用广泛的排序算法之一,其核心公式如下:
$$
Score(Q,D)=\sum_{i=1}^n IDF(q_i)\cdot\frac{f(q_i,D)+k_1⋅(1−b+b\cdot\frac{avgdl}{∣D∣})}{f(q_i,D)\cdot(k_1+1)}
$$
其中:
- $IDF(q_i)$: 查询词 $q_i$的逆文档频率,用于衡量一个词的普遍程度。越常见的词,IDF值越低。
- $f(q_i,D)$: 查询词 $q_i$在文档 DD 中的词频。
- $∣D∣$: 文档 D的长度。
- $avgdl$: 集合中所有文档的平均长度。
- $k_1,b$: 可调节的超参数。 $k_i$ 用于控制词频饱和度(一个词在文档中出现10次和100次,其重要性增长并非线性), $b$用于控制文档长度归一化的程度。
这种方法的优点是可解释性极强(每个维度都代表一个确切的词),无需训练,能够实现关键词的精确匹配,对于专业术语和特定名词的检索效果好。主要缺点是无法理解语义,例如它无法识别“汽车”和“轿车”是同义词,存在“词汇鸿沟”。
稀疏向量表示:
稀疏向量的核心思想是只存储非零值。例如,一个8维的向量 [0, 0, 0, 5, 0, 0, 0, 9],其大部分元素都是零。用稀疏格式表示,可以极大地节约空间。常见的稀疏表示法有两种:
字典 / 键值对 (Dictionary / Key-Value): 这种方式将非零元素的
索引(0-based) 作为键,值作为值。上面的向量可以表示为:1
2
3
4
5// {索引: 值}
{
"3": 5,
"7": 9
}Copy to clipboardErrorCopied坐标列表 (Coordinate list - COO): 这种方式通常用一个元组
(维度, [索引列表], [值列表])来表示。上面的向量可以表示为:1
(8, [3, 7], [5, 9])Copy to clipboardErrorCopied
这种格式在
SciPy等科学计算库中非常常见。
假设在一个包含5万个词的词汇表中,“西红柿”在第88位,“炒”在第666位,“蛋”在第999位,它们的BM25权重分别是1.2、0.8、1.5。那么它的稀疏表示(采用字典格式)就是:
1 | // {索引: 权重} |
如果采用坐标列表(COO)格式,它会是这样:
1 | (50000, [88, 666, 999], [1.2, 0.8, 1.5]) |
这两种格式都清晰地记录了文档的关键信息,但它们的局限性也很明显:如果我们搜索“番茄炒鸡蛋”,由于“番茄”和“西红柿”是不同的词条(索引不同),模型将无法理解它们的语义相似性。
密集向量
密集向量,也常被称为“语义向量”,是通过深度学习模型学习到的数据(如文本、图像)的低维、稠密的浮点数表示。这些向量旨在将原始数据映射到一个连续的、充满意义的“语义空间”中来捕捉“语义”或“概念”。在理想的语义空间中,向量之间的距离和方向代表了它们所表示概念之间的关系。一个经典的例子是 vector('国王') - vector('男人') + vector('女人') 的计算结果在向量空间中非常接近 vector('女王'),这表明模型学会了“性别”和“皇室”这两个维度的抽象概念。它的代表包括 Word2Vec、GloVe、以及所有基于 Transformer 的模型(如 BERT、GPT)生成的嵌入(Embeddings)。
其主要优点是能够理解同义词、近义词和上下文关系,泛化能力强,在语义搜索任务中表现卓越。但缺点也同样明显:可解释性差(向量中的每个维度通常没有具体的物理意义),需要大量数据和算力进行模型训练,且对于未登录词(OOV)的处理相对困难。
密集向量表示:
与稀疏向量不同,密集向量的所有维度都有值,因此使用数组 [] 来表示是最直接的方式。一个预训练好的语义模型在读取“西红柿炒蛋”后,会输出一个低维的密集向量:
1 | // 这是一个低维(比如1024维)的浮点数向量 |
这个向量本身难以解读,但它在语义空间中的位置可能与“番茄鸡蛋面”、“洋葱炒鸡蛋”等菜肴的向量非常接近,因为模型理解了它们共享“鸡蛋类菜肴”、“家常菜”、“酸甜口味”等核心概念。因此,当我们搜索“蛋白质丰富的家常菜”时,即使查询中没有出现任何原文关键词,密集向量也很有可能成功匹配到这份菜谱。
[!NOTE]
OOV(Out-of-Vocabulary)未登录词:指在模型训练时没有出现在词汇表中,但在实际使用时遇到的新词汇。传统的稀疏向量方法(如BM25)对OOV词汇会完全忽略,而现代的密集向量方法通过子词分割(如BPE、WordPiece)可以更好地处理OOV问题。
混合检索
稀疏向量和密集向量各有千秋,那么将它们结合起来,实现优势互补,就成了一个不错的选择。混合检索便是基于这个思路,通过结合多种搜索算法(最常见的是稀疏与密集检索)来提升搜索结果相关性和召回率。
- 主要目标:解决单一检索技术的局限性。例如,关键词检索无法理解语义,而向量检索则可能忽略掉必须精确匹配的关键词(如产品型号、函数名等)。混合检索旨在同时利用稀疏向量的精确性和密集向量的泛化性,以应对复杂多变的搜索需求。
技术原理与融合方法
混合检索通常并行执行两种检索算法,然后将两组异构的结果集融合成一个统一的排序列表。以下是两种主流的融合策略:
倒数排序融合 (Reciprocal Rank Fusion, RRF)
RRF 不关心不同检索系统的原始得分,只关心每个文档在各自结果集中的排名。其思想是:一个文档在不同检索系统中的排名越靠前,它的最终得分就越高。
其计分公式为:
$$
RRF_{score}(d) = \sum_{i=1}^k \frac{1}{rank_i(d) + c}
$$
其中:
- $d$ 是待评分的文档。
- $k$ 是检索系统的数量(这里是2,即稀疏和密集)。
- $rank_i(d)$是文档 dd 在第 $i$ 个检索系统中的排名。
- $c$是一个常数(通常设为60),用于降低排名靠前文档的相对权重,实现更稳健的排名融合。
加权线性组合
这种方法需要先将不同检索系统的得分进行归一化(例如,统一到 0-1 区间),然后通过一个权重参数 $\alpha$ 来进行线性组合。
$$
Hybrid_{score} = \alpha \cdot Dense_{score} + (1 - \alpha) \cdot Sparse_{score}
$$
通过调整 $\alpha$ 的值,可以灵活地控制语义相似性与关键词匹配在最终排序中的贡献比例。例如,在电商搜索中,可以调高关键词的权重;而在智能问答中,则可以侧重于语义。
优势与局限
| 优势 | 局限 |
|---|---|
| 召回率与准确率高:能同时捕获关键词和语义,显著优于单一检索。 | 计算资源消耗大:需要同时维护和查询两套索引。 |
| 灵活性强:可通过融合策略和权重调整,适应不同业务场景。 | 参数调试复杂:融合权重等超参数需要反复实验调优。 |
| 容错性好:关键词检索可部分弥补向量模型对拼写错误或罕见词的敏感性。 | 可解释性仍是挑战:融合后的结果排序理由难以直观分析。 |
查询构建
在实际应用中,我们常常需要处理更加复杂和多样化的数据,包括结构化数据(如SQL数据库)、半结构化数据(如带有元数据的文档)以及图数据。用户的查询也可能不仅仅是简单的语义匹配,而是包含复杂的过滤条件、聚合操作或关系查询。
查询构建(Query Construction)1 正是应对这一挑战的关键技术。它利用大语言模型(LLM)的强大理解能力,将用户的自然语言查询“翻译”成针对特定数据源的结构化查询语言或带有过滤条件的请求。这使得RAG系统能够无缝地连接和利用各种类型的数据,从而极大地扩展了其应用场景和能力。

文本到元数据过滤器
在构建向量索引时,常常会为文档块(Chunks)附加元数据(Metadata),例如文档来源、发布日期、作者、章节、类别等。这些元数据为我们提供了在语义搜索之外进行精确过滤的可能。
自查询检索器(Self-Query Retriever) 是LangChain中实现这一功能的核心组件。它的工作流程如下:
- 定义元数据结构:首先,需要向LLM清晰地描述文档内容和每个元数据字段的含义及类型。
- 查询解析:当用户输入一个自然语言查询时,自查询检索器会调用LLM,将查询分解为两部分:
- 查询字符串(Query String):用于进行语义搜索的部分。
- 元数据过滤器(Metadata Filter):从查询中提取出的结构化过滤条件。
- 执行查询:检索器将解析出的查询字符串和元数据过滤器发送给向量数据库,执行一次同时包含语义搜索和元数据过滤的查询。
例如,对于查询“关于2022年发布的机器学习的论文”,自查询检索器会将其解析为:
- 查询字符串: “机器学习的论文”
- 元数据过滤器:
year == 2022
文本到Cypher
除了处理扁平化的元数据,查询构建技术还能应用于更复杂的数据结构,如图数据库。
什么是 Cypher?
Cypher 是图数据库(如 Neo4j)中最常用的查询语言,其地位类似于 SQL 之于关系数据库。它采用一种直观的方式来匹配图中的模式和关系,例如 (:Person {name:"Tomaz"})-[:LIVES_IN]->(:Country {name:"Slovenia"}) 描述了一个人和一个国家以及他们之间的“居住在”关系。
文本到Cypher”的原理
与“文本到元数据过滤器”类似,“文本到Cypher”技术利用大语言模型(LLM)将用户的自然语言问题直接翻译成一句精准的 Cypher 查询语句。LangChain 提供了相应的工具链(如 GraphCypherQAChain),其工作流程通常是:
- 接收用户的自然语言问题。
- LLM 根据预先提供的图谱模式(Schema),将问题转换为 Cypher 查询。
- 在图数据库上执行该查询,获取精确的结构化数据。
- (可选)将查询结果再次交由 LLM,生成通顺的自然语言答案。
由于生成有效的 Cypher 查询是一项复杂的任务,通常使用性能较强的 LLM 来确保转换的准确性。通过这种方式,用户可以用最自然的方式与高度结构化的图数据进行交互,极大地降低了数据查询的门槛。
文本到SQL
在数据世界中,除了向量数据库能够处理的非结构化数据,关系型数据库(如 MySQL, PostgreSQL, SQLite)同样是存储和管理结构化数据的重点。文本到SQL(Text-to-SQL)正是为了打破人与结构化数据之间的语言障碍而生。它利用大语言模型(LLM)将用户的自然语言问题,直接翻译成可以在数据库上执行的SQL查询语句。

挑战
- “幻觉”问题:LLM 可能会“想象”出数据库中不存在的表或字段,导致生成的SQL语句无效。
- 对数据库结构理解不足:LLM 需要准确理解表的结构、字段的含义以及表与表之间的关联关系,才能生成正确的
JOIN和WHERE子句。 - 处理用户输入的模糊性:用户的提问可能存在拼写错误或不规范的表达(例如,“上个月的销售冠军是谁?”),模型需要具备一定的容错和推理能力。
优化策略
- 提供精确的数据库模式:这是最基础也是最关键的一步。我们需要向LLM提供数据库中相关表的
CREATE TABLE语句。这就像是给了LLM一张地图,让它了解数据库的结构,包括表名、列名、数据类型和外键关系。 - 提供少量高质量的示例:在提示(Prompt)中加入一些“问题-SQL”的示例对,可以极大地提升LLM生成查询的准确性。这相当于给了LLM几个范例,让它学习如何根据相似的问题构建查询。
- 利用RAG增强上下文:这是更进一步的策略。我们可以像RAGFlow一样,为数据库构建一个专门的“知识库”2,其中不仅包含表的DDL(数据定义语言),还可以包含:
- 表和字段的详细描述:用自然语言解释每个表是做什么的,每个字段代表什么业务含义。
- 同义词和业务术语:例如,将用户的“花费”映射到数据库的
cost字段。 - 复杂的查询示例:提供一些包含
JOIN、GROUP BY或子查询的复杂问答对。 当用户提问时,系统首先从这个知识库中检索最相关的信息(如相关的表结构、字段描述、相似的Q&A),然后将这些信息和用户的问题一起组合成一个内容更丰富的提示,交给LLM生成最终的SQL查询。这种方式极大地降低了“幻觉”的风险,提高了查询的准确度。
- **错误修正与反思 (Error Correction and Reflection)**:在生成SQL后,系统会尝试执行它。如果数据库返回错误,可以将错误信息反馈给LLM,让它“反思”并修正SQL语句,然后重试。这个迭代过程可以显著提高查询的成功率。
查询重构与分发
用户的原始问题往往不是最优的检索输入。它可能过于复杂、包含歧义,或者与文档的实际措辞存在偏差。为了解决这些问题,需要在检索之前对用户的查询进行“预处理”,这就是查询重构与分发。
两个关键技术:
- 查询翻译(Query Translation):将用户的原始问题转换成一个或多个更适合检索的形式。
- 查询路由(Query Routing):根据问题的性质,将其智能地分发到最合适的数据源或检索器。
查询翻译
减弱用户自然语言提问与文档库中存储信息之间的“语义差距”。通过重写、分解或扩展查询,我们可以显著提升检索的准确率。
提示工程
最直接的查询重构方法。通过精心设计的提示词(Prompt),引导 LLM 将用户的原始查询改写得更清晰、更具体,或者转换成一种更利于检索的叙述风格。
在第二节查询构建的代码示例中,我们发现 SelfQueryRetriever 无法正确处理“时间最短的视频”这类需要排序或进行比较的查询。
为了解决这个问题,可以采用一种更高级的提示工程技巧:让 LLM 直接构建出查询指令。
这种方法的思路是,要求 LLM 直接分析用户的意图,并生成一个结构化(例如 JSON 格式)的指令,告诉我们的代码应该如何操作。对于“时间最短的视频”这个问题,我们期望 LLM 能直接告诉我们:“请按‘时长’字段进行升序排序,并返回第一条结果”。
下面,来看看如何修改代码来实现这一思路。我们不再使用 SelfQueryRetriever,而是直接与 LLM 交互,并根据其返回的指令在代码中执行排序逻辑。
多查询分解 (Multi-query)
当用户提出一个复杂的问题时,直接用整个问题去检索可能效果不佳,因为它可能包含多个子主题或意图。分解技术的核心思想是将这个复杂问题拆分成多个更简单、更具体的子问题。然后,系统分别对每个子问题进行检索,最后将所有检索到的结果合并、去重,形成一个更全面的上下文,再交给 LLM 生成最终答案。
示例:
- 原始问题:“在《流浪地球》中,刘慈欣对人工智能和未来社会结构有何看法?”
- 分解后的子问题:
- “《流浪地球》中描述的人工智能技术有哪些?”
- “《流浪地球》中描绘的未来社会是怎样的?”
- “刘慈欣关于人工智能的观点是什么?”
退步提示(Step-Back Prompting)
退步提示是由 Google DeepMind 团队提出的一种旨在提升大语言模型推理能力的提示工程技巧2。当面对一个细节繁多或过于具体的问题时,模型直接作答(即便是使用思维链)也容易出错。退步提示通过引导模型“退后一步”来解决这个问题。
其核心流程分为两步:
(1)抽象化:首先,引导 LLM 从用户的原始具体问题中,生成一个更高层次、更概括的“退步问题”(Step-back Question)。这个退步问题旨在探寻原始问题背后的通用原理或核心概念。
(2)推理:接着,系统会先获取“退步问题”的答案(例如,一个物理定律、一段历史背景等),然后将这个通用原理作为上下文,再结合原始的具体问题,进行推理并生成最终答案。
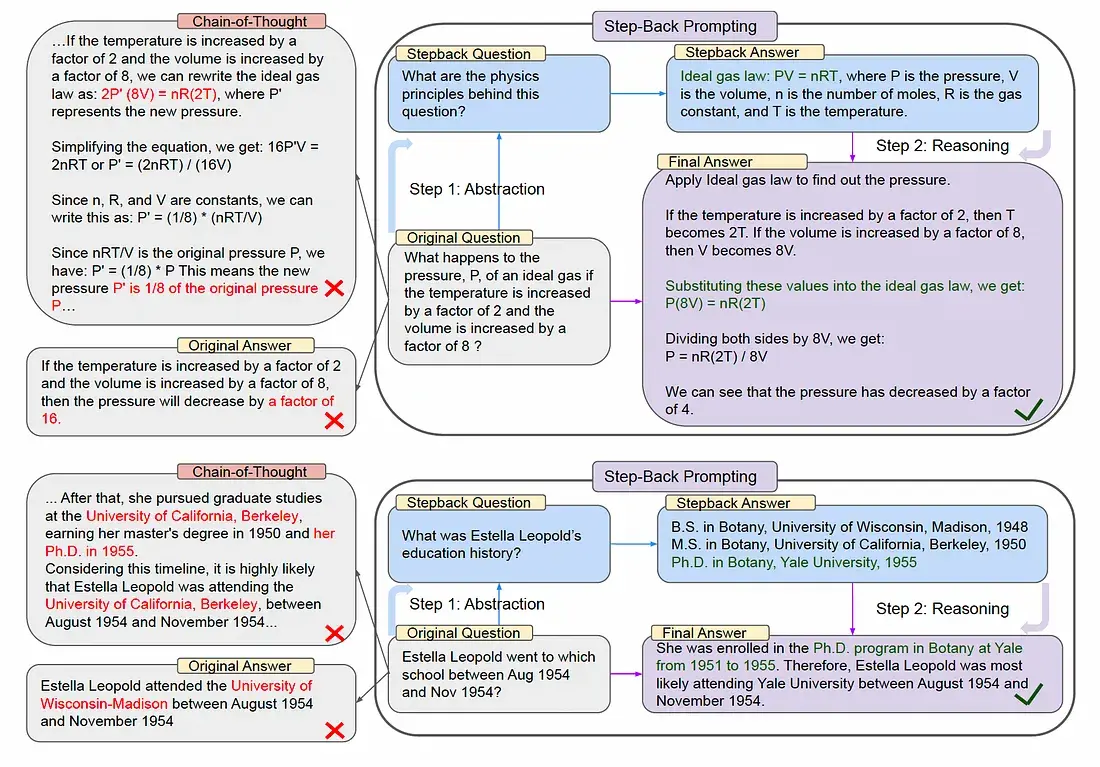
示例:
- 原始问题:“如果理想气体的温度增加2倍,体积增加8倍,其压力会如何变化?”
- 退步问题:“这个问题背后的物理原理是什么?”
- 推理过程:首先回答退步问题,得到“理想气体定律 PV=nRT”。然后基于这个定律,代入具体数值进行计算,最终得出压力变为原来的1/4。
通过先检索或生成高层知识,再进行具体推理,退步提示能够帮助模型构建一个更坚实的逻辑基础,从而提高在复杂问答场景下的准确性。
假设性文档嵌入 (HyDE)
假设性文档嵌入(Hypothetical Document Embeddings, HyDE)是一种无需微调即可显著提升向量检索质量的查询改写技术,由 Luyu Gao 等人在其论文中首次提出3。其核心是解决一个普遍存在于检索任务中的难题:用户的查询(Query)通常简短、关键词有限,而数据库中存储的文档则内容详实、上下文丰富,两者在语义向量空间中可能存在“鸿沟”,导致直接用查询向量进行搜索效果不佳。Zilliz 的一篇技术博客4也对该技术进行了深入浅出的解读。
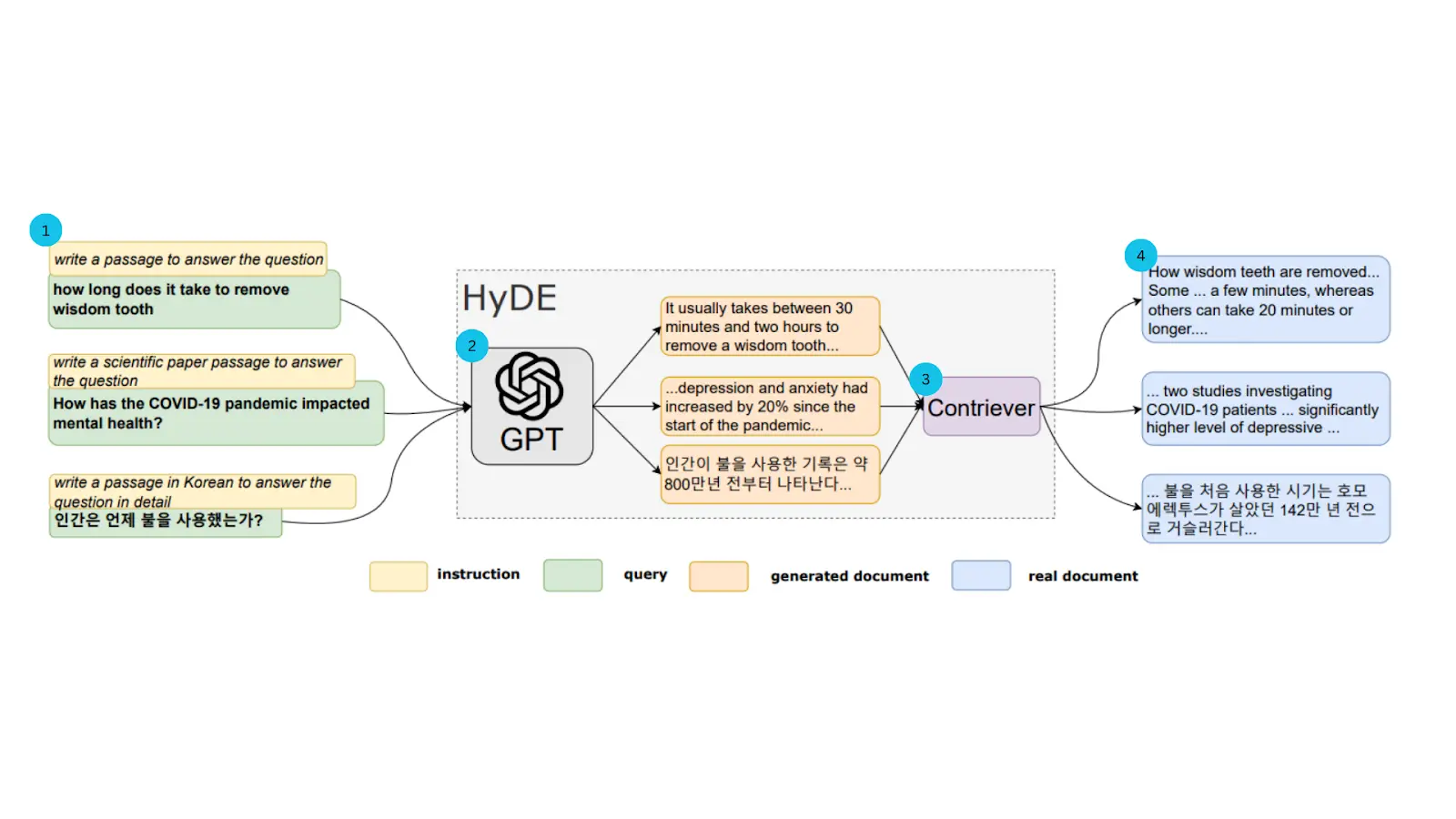
HyDE 通过一种巧妙的方式来“绕过”这个问题:它不直接使用用户的原始查询,而是先利用一个生成式大语言模型(LLM)来生成一个“假设性”的、能够完美回答该查询的文档。然后,HyDE 将这个内容详实的假设性文档进行向量化,用其生成的向量去数据库中寻找与之最相似的真实文档。HyDE 的工作流程可以分为三个步骤:
(1)生成:当接收到用户查询时,首先调用一个生成式 LLM(例如,GPT-3.5)。提示该模型根据查询生成一个详细的、可能是理想答案的文档。这个文档不必完全符合事实,但它必须在语义上与一个好的答案高度相关。
(2)编码:将上一步生成的假设性文档输入到一个对比编码器(如 Contriever)中,将其转换为一个高维向量嵌入。这个向量在语义上代表了一个“理想答案”的位置。
(3)检索:使用这个假设性文档的向量,在向量数据库中执行相似性搜索,找出与这个“理想答案”最接近的真实文档。这些被检索出的文档将作为最终的上下文信息。
通过这种方式,HyDE 将困难的“查询到文档”的匹配问题,转化为了一个相对容易的“文档到文档”的匹配问题,从而提升检索的准确率。
查询路由
查询路由(Query Routing) 是用于优化复杂 RAG 系统的一项关键技术。当系统接入了多个不同的数据源或具备多种处理能力时,就需要一个“智能调度中心”来分析用户的查询,并动态选择最合适的处理路径。其本质是替代硬编码规则,通过语义理解将查询分发至最匹配的数据源、处理组件或提示模板,从而提升系统的效率与答案的准确性。
应用场景
查询路由的应用场景十分广泛。
- 数据源路由:这是最常见的场景。根据查询意图,将其路由到不同的知识库。例如:
- 查询“最新的 iPhone 有什么功能?” -> 路由到产品文档向量数据库。
- 查询“我上次订购了什么?” -> 路由到用户历史SQL数据库(执行Text-to-SQL)。
- 查询“A公司和B公司的投资关系是怎样的?” -> 路由到企业知识图谱数据库。
- 组件路由:根据问题的复杂性,将其分配给不同的处理组件,以平衡成本和效果。
- 简单FAQ → 直接进行向量检索,速度快、成本低。
- 复杂操作或需要与外部API交互 → 调用 Agent 来执行任务。
- 提示模板路由:为不同类型的任务动态选择最优的提示词模板,以优化生成效果。
- 数学问题 → 选用包含分步思考(Step-by-Step)逻辑的提示模板。
- 代码生成 → 选用专门为代码优化过的提示模板。
实现方法
基于LLM的意图识别
通过设计一个包含路由选项的提示词,让大模型直接对用户的查询进行分类,并输出一个代表路由选择的标签。
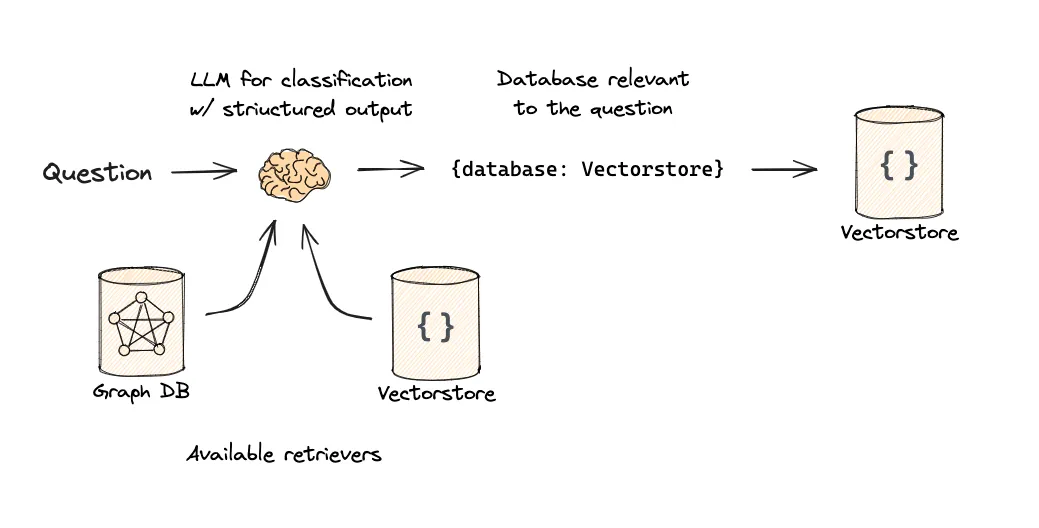
- 实现流程:
- 定义清晰的路由选项(例如,数据源名称、功能分类)。
- LLM 分析查询并输出决策标签。
- 代码根据标签调用相应的检索器或工具。
该方法的核心在于构建一个“分类-分发”的流水线。这里以一个菜谱问答为例,系统需要根据用户提问的菜系(川菜、粤菜或其他)调用不同的专家模型。
嵌入相似性路由
这种方法不依赖 LLM 进行分类,延迟更低。它通过计算用户查询与预设的“路由示例语句”之间的向量嵌入相似度来做出决策。
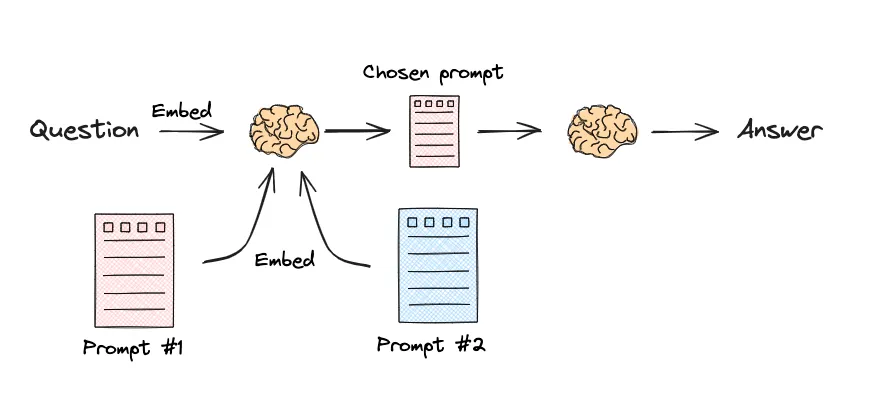
第一步:定义路由描述并向量化
为每个路由创建一个详细的文本描述,并使用嵌入模型将其转换为向量,供后续相似度计算使用。
第二步:定义目标链
创建路由最终要分发到的目标处理链,并用一个字典route_map将路由名称和链对应起来。
第三步:定义路由函数
定义一个route函数,接收用户问题,计算与各路由描述的相似度,选择最相似的路由并调用相应的处理链。
第四步:组合并调用
最后,将route函数包装成一个RunnableLambda,形成一个完整的、可执行的路由链。
检索进阶
在基础的 RAG 流程中,依赖向量相似度从知识库中检索信息。不过,这种方法存在一些固有的局限性,例如最相关的文档不总是在检索结果的顶端,以及语义理解的偏差等。为了构建更强大、更精准的生产级 RAG 应用,需要引入更高级的检索技术。
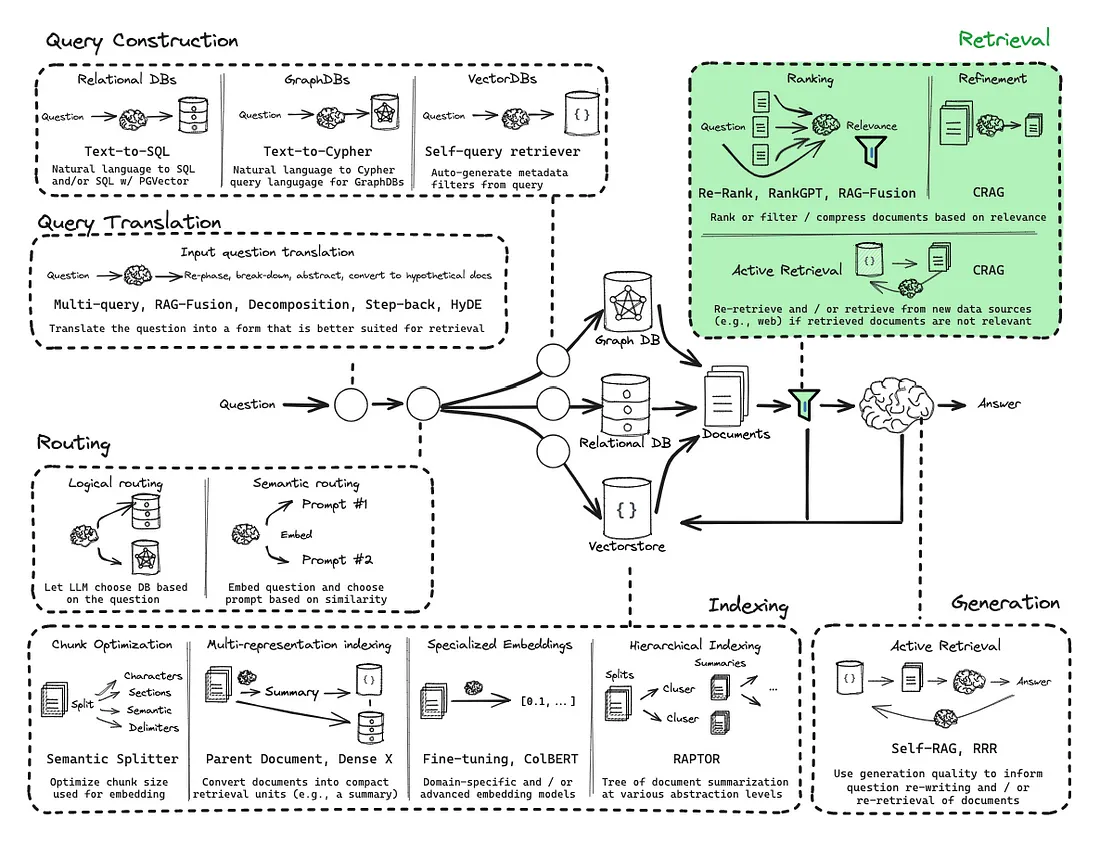
重排序(Re-ranking)
RRF
一种简单而有效的零样本重排方法,不依赖于任何模型训练,而是纯粹基于文档在多个检索器(例如,一个稀疏检索器和一个密集检索器)结果列表中的排名俩计算最终分数。
如果文档在多个检索器结果中都排名靠前,那它可能更重要。RRF通过计算排名的倒数($\frac1{rank}$)来为文档打分,有效融合了不同检索策略的优势。但如果只考虑排名信息,会忽略原始的相似度分数。
RankLLM / LLM-based Reranker
ankLLM 代表了一类直接利用大型语言模型本身来进行重排的方法1。其基本逻辑非常直观:既然 LLM 最终要负责根据上下文来生成答案,那么为什么不直接让它来判断哪些上下文最相关呢?
这种方法通过一个精心设计的提示词来实现。该提示词会包含用户的查询和一系列候选文档(通常是文档的摘要或关键部分),然后要求 LLM 以特定格式(如 JSON)输出一个排序后的文档列表,并给出每个文档的相关性分数。
提示词示例:
1 | 以下是一个文档列表,每个文档都有一个编号和摘要。同时提供一个问题。请根据问题,按相关性顺序列出您认为需要查阅的文档编号,并给出相关性分数(1-10分)。请不要包含与问题无关的文档。 |
Cross-Encoder 重排
交叉编码器能提供出色的重排精度。工作原理是将查询(Query)和每个候选文档(Document)拼接成一个单一的输入(例如,[CLS] query [SEP] document [SEP]),然后将这个整体输入到一个预训练的 Transformer 模型(如 BERT)中,模型最终会输出一个单一的分数(通常在 0 到 1 之间),这个分数直接代表了文档与查询的相关性。
[!NOTE]
交叉编码器会将两个输入句子拼接后一起编码&],直接输出一个相关性或分类分数,而不是分别生成独立的向量再计算相似度。这种方式能捕捉句子间的细粒度交互,因此在分类、重排序等高精度任务中表现更好,但推理速度较慢、计算成本高。
[SEP] 是在 BERT 这类基于 Transformer 架构的模型中,用于分隔不同文本片段(如查询和文档)的特殊标记。

上图清晰地展示了 Cross-Encoder 的工作流程:
- 初步检索:搜索引擎首先从知识库中召回一个初始的文档列表(例如,前 50 篇)。
- 逐一评分:对于列表中的每一篇文档,系统都将其与原始查询配对,然后发送给 Cross-Encoder 模型。
- 独立推理:模型对每个“查询-文档”对进行一次完整的、独立的推理计算,得出一个精确的相关性分数。
- 返回重排结果:系统根据这些新的分数对文档列表进行重新排序,并将最终结果返回给用户。
这个流程凸显了其高精度的来源(同时分析查询和文档),也解释了其高延迟的原因(需要N次独立的模型推理)。
常见的 Cross-Encoder 模型包括 ms-marco-MiniLM-L-12-v2、ms-marco-TinyBERT-L-2-v2 等。
ColBERT 重排
ColBERT(Contextualized Late Interaction over BERT)是一种创新的重排模型,它在 Cross-Encoder 的高精度和双编码器(Bi-Encoder)的高效率之间取得了平衡3。采用了一种“后期交互”机制。
其工作流程如下:
- 独立编码:ColBERT 分别为查询(Query)和文档(Document)中的每个 Token 生成上下文相关的嵌入向量。这一步是独立完成的,可以预先计算并存储文档的向量,从而加快查询速度。
- 后期交互:在查询时,模型会计算查询中每个 Token 的向量与文档中每个 Token 向量之间的最大相似度(MaxSim)。
- 分数聚合:最后,将查询中所有 Token 得到的最大相似度分数相加,得到最终的相关性总分。
通过这种方式,ColBERT 避免了将查询和文档拼接在一起进行昂贵的联合编码,同时又比单纯比较单个 [CLS] 向量的双编码器模型捕捉了更细粒度的词汇级交互信息。
重排方法对比
为了更直观地理解不同重排方法的特点和适用场景,下表对讨论过的几种主流方法进行了总结:
| 特性 | RRF | RankLLM | Cross-Encoder | ColBERT |
|---|---|---|---|---|
| 核心机制 | 融合多个排名 | LLM 推理,生成排序列表 | 联合编码查询与文档,计算单一相关分 | 独立编码,后期交互 |
| 计算成本 | 低(简单数学计算) | 中 (API 费用与延迟) | 高(N次模型推理) | 中(向量点积计算) |
| 交互粒度 | 无(仅排名) | 概念/语义级 | 句子级(Query-Doc Pair) | Token 级 |
| 适用场景 | 多路召回结果融合 | 高价值语义理解场景 | Top-K 精排 | Top-K 重排 |
压缩(Compression)
“压缩”技术旨在解决一个常见问题:初步检索到的文档块(Chunks)虽然整体上与查询相关,但可能包含大量无关的“噪音”文本。将这些未经处理的、冗长的上下文直接提供给 LLM,不仅会增加 API 调用的成本和延迟,还可能因为信息过载而降低最终生成答案的质量。
压缩的目标就是对检索到的内容进行“压缩”和“提炼”,只保留与用户查询最直接相关的信息。这可以通过两种主要方式实现:
- 内容提取:从文档中只抽出与查询相关的句子或段落。
- 文档过滤:完全丢弃那些虽然被初步召回,但经过更精细判断后认为不相关的整个文档。
LangChain 的 ContextualCompressionRetriever
LangChain 提供了一个强大的组件 ContextualCompressionRetriever 来实现上下文压缩4。它像一个包装器,包裹在基础的检索器(如 FAISS.as_retriever())之上。当基础检索器返回文档后,ContextualCompressionRetriever 会使用一个指定的 DocumentCompressor 对这些文档进行处理,然后再返回给调用者。
LangChain 内置了多种 DocumentCompressor:
LLMChainExtractor: 这是最直接的压缩方式。它会遍历每个文档,并利用一个 LLM Chain 来判断并提取出其中与查询相关的部分。这是一种“内容提取”。LLMChainFilter: 这种压缩器同样使用 LLM,但它做的是“文档过滤”。它会判断整个文档是否与查询相关,如果相关,则保留整个文档;如果不相关,则直接丢弃。EmbeddingsFilter: 这是一种更快速、成本更低的过滤方法。它会计算查询和每个文档的嵌入向量之间的相似度,只保留那些相似度超过预设阈值的文档。
自定义重排器与压缩管道
在前面我们就提到根据实际应用,需要自己进行一些功能的实现。这里以 ColBERT 为例,展示如何集成未被官方支持的功能。
整个探索和实现过程如下:
- 从官方文档出发:首先,通过 LangChain 官方文档,了解到可以通过
DocumentCompressorPipeline来组合多个压缩器和文档转换器。 - 需求缺口:希望使用 ColBERT 模型进行重排,但发现 LangChain 并没有内置的
ColBERT重排器。 - 分析示例与源码:回头分析
ContextualCompressionRetriever的用法和源码。我们发现,其处理逻辑分为两步:首先使用base_retriever获取原始文档,然后将这些文档交给base_compressor进行压缩或重排。这说明,实现自定义后处理(如重排)功能的关键在于base_compressor。 - 定位核心基类:通过f12查看源码,确定
base_compressor参数接收的是BaseDocumentCompressor类型的对象。这就是实现自定义功能的核心切入点。 - 参考与实现:最后,参考 LangChain 中其他重排器的实现方式,通过继承
BaseDocumentCompressor基类并实现其关键方法,创建自己的ColBERTReranker类。
PS:如果代码基础薄弱,想借助大模型帮你完成
ColBERTReranker,需要提供给大模型的关键信息:BaseDocumentCompressor的源码和ContextualCompressionRetriever的源码及其使用示例、你的明确目标(实现 ColBERT 重排逻辑)、以及 LangChain 中其他重排器的代码作为参考。信息越充分,模型生成的代码越准确。
LlamaIndex 中的检索压缩
LlamaIndex 同样提供了封装好的压缩功能,其代表是 SentenceEmbeddingOptimizer5。它也是一个后处理器(Node Postprocessor),工作在检索之后。
它的工作原理是,对于每个检索到的文档,将其分解成句子。然后计算每个句子与用户查询的嵌入相似度,最后只保留那些相似度最高的句子,从而“优化”文档,去除无关信息。
校正(Correcting)
传统的 RAG 流程有一个隐含的假设:检索到的文档总是与问题相关且包含正确答案。然而在现实世界中,检索系统可能会失败,返回不相关、过时或甚至完全错误的文档。如果将这些“有毒”的上下文直接喂给 LLM,就可能导致幻觉(Hallucination)或产生错误的回答。
校正检索(Corrective-RAG, C-RAG) 正是为解决这一问题而提出的一种策略6。思路是引入一个“自我反思”或“自我修正”的循环,在生成答案之前,对检索到的文档质量进行评估,并根据评估结果采取不同的行动。
C-RAG 的工作流程可以概括为 “检索-评估-行动” 三个阶段:
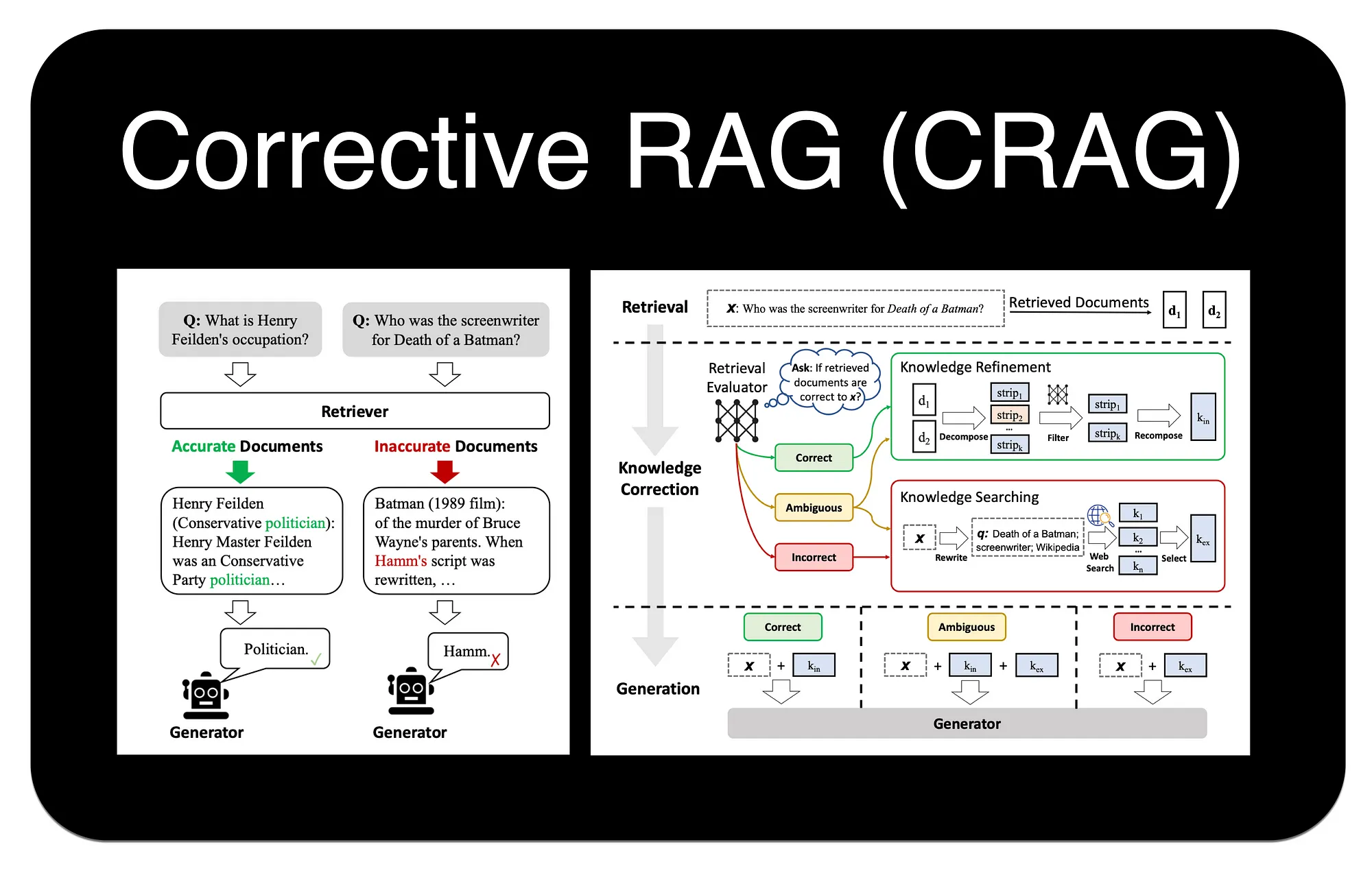
- 检索 (Retrieve) :与标准 RAG 一样,首先根据用户查询从知识库中检索一组文档。
- 评估 (Assess) :这是 C-RAG 的关键步骤。如图所示,一个“检索评估器 (Retrieval Evaluator)”会判断每个文档与查询的相关性,并给出“正确 (Correct)”、“不正确 (Incorrect)”或“模糊 (Ambiguous)”的标签。
- 行动 (Act) :根据评估结果,系统会进入不同的知识修正与获取流程:
- 如果评估为“正确”:系统会进入“知识精炼 (Knowledge Refinement)”环节。如图,它会将原始文档分解成更小的知识片段 (strips),过滤掉无关部分,然后重新组合成更精准、更聚焦的上下文,再送给大模型生成答案。
- 如果评估为“不正确”:系统认为内部知识库无法回答问题,此时会触发“知识搜索 (Knowledge Searching)”。它会先对原始查询进行“查询重写 (Query Rewriting)”,生成一个更适合搜索引擎的查询,然后进行 Web 搜索,用外部信息来回答问题。
- 如果评估为“模糊”:同样会触发“知识搜索”,但通常会直接使用原始查询进行 Web 搜索,以获取额外信息来辅助生成答案。
通过这种方式,C-RAG 极大地增强了 RAG 系统的鲁棒性。不再盲目信任检索结果,而是增加了一个“事实核查”层,能够在检索失败时主动寻求外部帮助,从而有效减少幻觉,提升答案的准确性和可靠性。
在 LangChain 的 langgraph 库中,可以利用其图结构来灵活地构建这种带有条件判断和循环的复杂 RAG 流程。
